Input vs Output Privacy
- Abhishek Tiwari
- Research
- 10.59350/t55aq-2yb63
- Crossref
- November 3, 2024
Table of Contents
Privacy in data systems has traditionally focused on protecting sensitive information as it enters a system - what we call input privacy. However, as systems become more complex and capable of inferring sensitive information from seemingly harmless data, the importance of output privacy has gained significant attention. Let’s explore these two crucial aspects of privacy protection and understand how different techniques address them.
What is Input Privacy?
Input privacy focuses on protecting sensitive data at the point of collection and storage. Think of it as a secure vault where valuable items are stored. The primary goal is to ensure that unauthorised parties cannot access the raw, sensitive information. This includes protecting data like social security numbers, medical records, or financial information when they’re first collected and stored in a system.
Think of sending a sealed letter through the postal service. When you write personal information in a letter, seal it in an envelope, and mail it, you’re implementing input privacy. The postal service handles and delivers your letter without seeing its contents. They can see the delivery address and handle the physical envelope, but the actual message remains private. This is similar to how input privacy works in data systems - the service (like the postal system) can process and route the information (like delivering your letter) without accessing the sensitive content inside. The envelope acts as the privacy mechanism, much like encryption protects sensitive data in modern systems.
When we implement input privacy, we’re essentially creating a fortress around our data. This might involve encryption, access controls, and secure transmission protocols. The fundamental assumption is that if we can protect the data at rest and in transit, we’ve succeeded in maintaining privacy.
In the context of machine learning, input privacy encompasses not just the raw training data, but the entire training pipeline, including feature engineering, model architecture, and training dynamics. When a healthcare organization trains a diagnostic model, for instance, input privacy must protect not only patient records but also derived features, gradient updates, and model parameters during training.
Understanding Output Privacy
Output privacy, on the other hand, is concerned with protecting sensitive information from being revealed through the results of computations, predictions, aggregations, or queries on the data. It’s like ensuring that even if someone can see the shadow of an object, they can’t determine its exact shape or nature.
The challenge with output privacy is more nuanced than input privacy. Even if individual data points are protected, the aggregated results or patterns might reveal sensitive information about individuals or groups. This is where techniques like differential privacy become crucial, adding carefully calibrated noise to results to protect individual privacy while maintaining statistical utility.
In ML, output privacy represents perhaps the most challenging aspect of ML systems. ML models can leak training data through various subtle channels. A model trained on sensitive medical data might reveal patient information not just through direct predictions, but through confidence scores, decision boundaries, and even timing variations in responses. As matter of fact, output privacy is a concern for any ML model whose predictions are made available to end-users. Deliberate attempts to break output privacy are often referred to as reverse engineering attacks.
A good example of output privacy is census data. The US Census Bureau must publish population statistics while protecting individual privacy. In 2010, researchers found they could reconstruct 46% of individual responses by combining census data with commercial databases. They were able to accurately identify specific individuals by linking these records with commercial databases and determine sensitive attributes like age, gender, race, and ethnicity for identified individuals. Consider a census block in a small town:
Total Population: 25
Adults (18+): 18
Children: 7
Households: 8
Average Household Size: 3.125
A privacy protected output using differential privacy,
Total Population: 24
Adults (18+): 19
Children: 5
Households: 7
Average Household Size: 3.428
The small discrepancies in the privacy-protected output make it mathematically impossible to reconstruct the exact original data while maintaining the statistical utility of the information for most legitimate uses.
The Interplay
Input and output privacy are not mutually exclusive - they’re complementary approaches that work together to provide comprehensive privacy protection. A system might have strong input privacy controls but still be vulnerable to inference attacks through its outputs. Conversely, robust output privacy measures might be undermined by weak input protection.
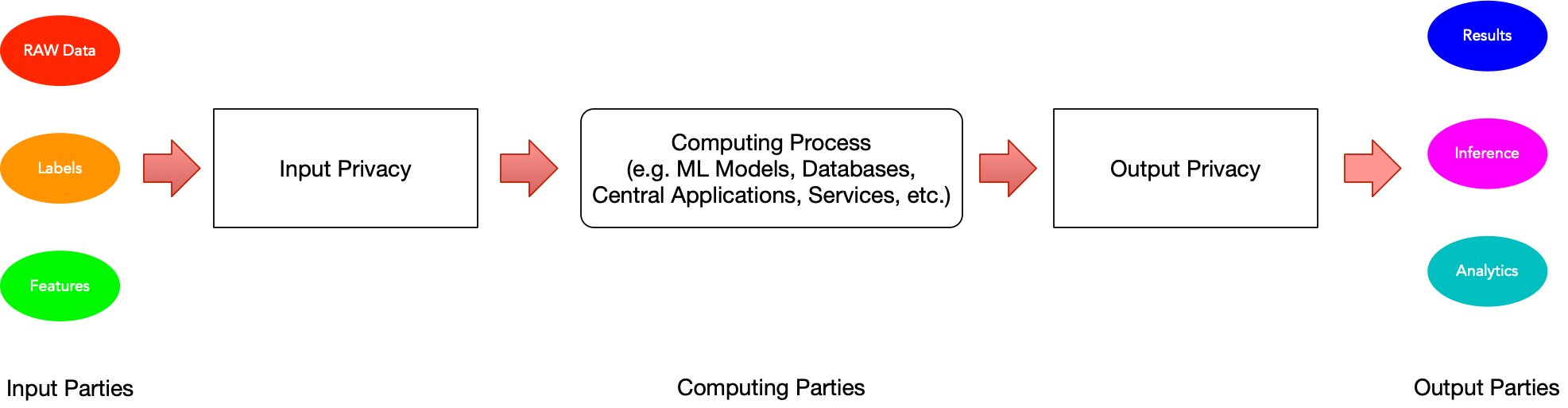
Consider a medical research database. Input privacy ensures that patient records are encrypted and access-controlled. Output privacy ensures that when researchers query the database for statistics, the results don’t inadvertently reveal information about specific individuals.
Comparing Privacy Techniques
Here’s how various privacy-preserving techniques compare in terms of their support for input and output privacy:
| Technique | Input Privacy Support | Output Privacy Support | Key Characteristics |
|---|---|---|---|
| Encryption | Strong | Limited | Protects data at rest and in transit; doesn’t address inference from results |
| Access Control | Strong | None | Controls who can access raw data; no protection for computed results |
| Differential Privacy | None | Strong | Adds mathematical noise to outputs; doesn’t protect raw data |
| Secure Multi-party Computation | Strong | Moderate | Enables computation on encrypted data; some output inference still possible |
| Homomorphic Encryption | Strong | Moderate | Allows computation on encrypted data; output may reveal patterns |
| K-anonymity | Moderate | Moderate | Generalizes data attributes; protects both input and output to some degree |
| Zero-knowledge Proofs | Strong | Strong | Proves statements about data without revealing the data; expensive computationally |
| Data Masking | Strong | Limited | Replaces sensitive data with realistic alternatives; doesn’t protect against correlation |
| Federated Learning | Strong | Moderate | Keeps raw data local; model outputs may leak information |
The Future of Privacy Protection
As AI and machine learning systems become more sophisticated, the distinction between input and output privacy becomes increasingly important. These systems can often infer sensitive information from seemingly innocuous data patterns, making output privacy as crucial as traditional input protection.
The future of privacy protection likely lies in hybrid approaches that address both aspects comprehensively. This might include:
- Advanced cryptographic techniques that protect both data and computational results
- AI-powered privacy systems that can anticipate and prevent potential inference attacks
- New regulatory frameworks that recognize and address both input and output privacy concerns
Conclusion
Understanding the distinction between input and output privacy is crucial for designing truly private systems. While input privacy provides the foundation for data protection, output privacy ensures that this protection extends to the insights and results derived from the data. As technology evolves, we must continue to develop and implement techniques that address both aspects effectively.
Organizations and developers must carefully consider both dimensions when designing privacy-preserving systems. The choice of specific techniques should be based on the particular requirements of the application, the sensitivity of the data, and the intended use cases. Only by addressing both input and output privacy can we build systems that truly protect sensitive information in our increasingly data-driven world.


